OpenAI Whisper: 빠르고 쉽게 STT(Speech-to-Text) 사용하기
OpenAI Whisper 모델을 활용하여 MP3 파일을 텍스트로 변환하는 방법을 알아보자. 설치부터 사용 예시까지 단계별 가이드. 리눅스와 윈도우 환경에서의 ffmpeg 및 Scoop 설치 방법 포함. Whisper로 더욱 정확한 STT 결과 얻기.

STT(Speech-To-Text)를 사용하기 위해서 몇가지 모델들을 찾아보다가 최근 OpenAI에서 개발한 Whisper 모델을 찾을 수 있었다.
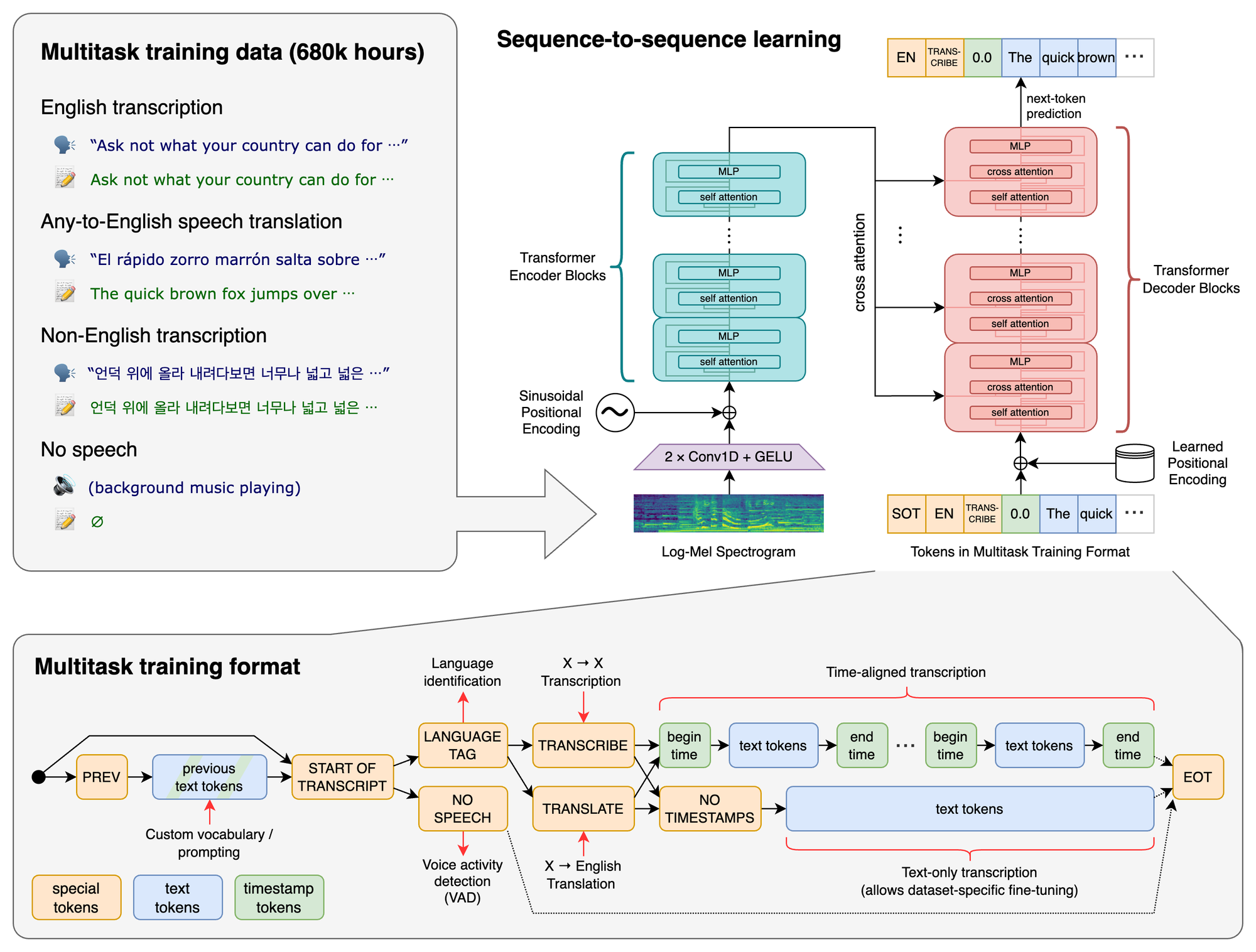
Whisper는 Transformer를 기반으로 만들어진 ASR모델이다.
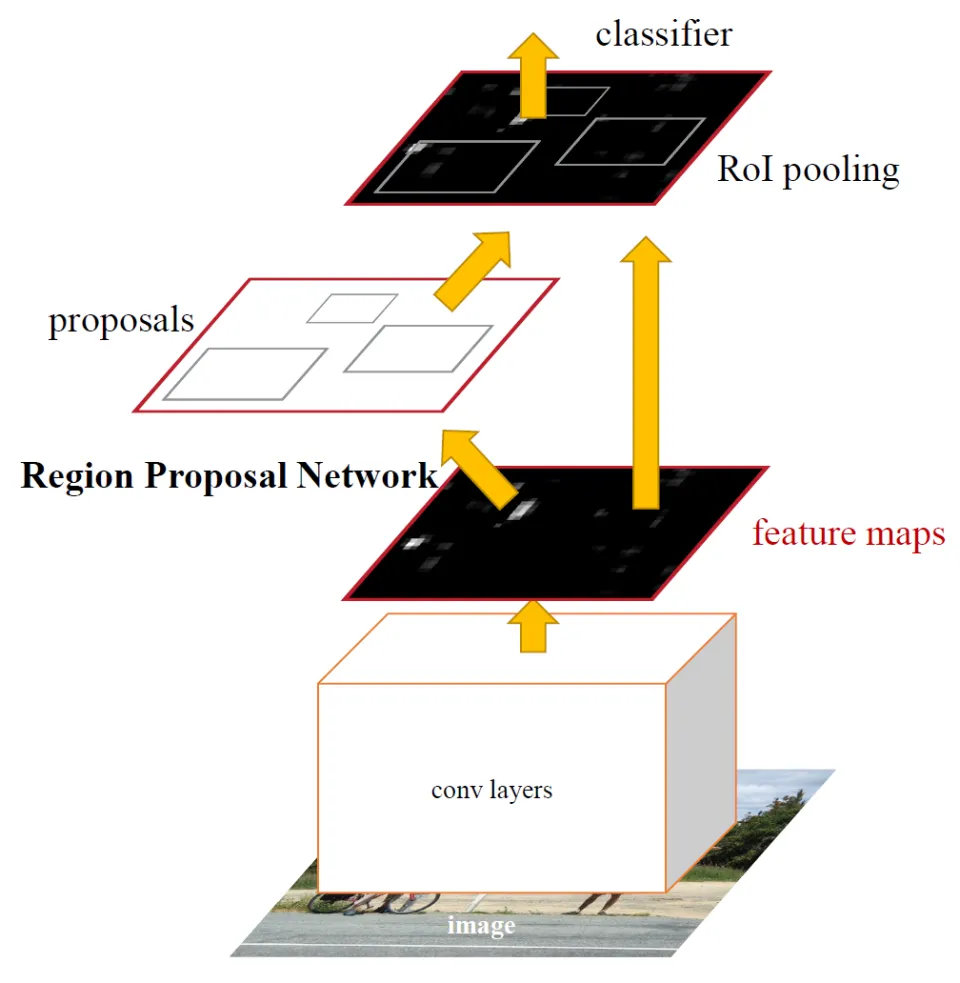
github페이지의 자료를 가져와 보면 Transformer에다가 디코더가 추가된 형태인 것을 알수있으며, 토큰의 사용으로 다양한 작업을 수행할 수 있다.
아래는 github페이지의 이미지이다.
pip install git+https://github.com/openai/whisper.git 로 whisper를 설치한다.
whisper를 사용하려면 ffmpeg가 설치되어있어야 한다.
ffmpeg를 설치하기엔 리눅스가 편하다. 하지만 필자는 현재 윈도우를 사용중이므로 Chocolatey나 Scoop과 같은 패키지 매니저가 필요하다.
여기서는 Scoop을 사용하려한다. Scoop을 설치해보자.
윈도우 powershell을 열자
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
Invoke-RestMethod -Uri https://get.scoop.sh | Invoke-Expression
이제 Scoop 설치는 완료되었다.
마지막으로 ffmpeg를 설치하자!
scoop install ffmpeg
아래 테스트 명령어로 mp3파일을 텍스트화 해볼 수 있다.
whisper test2.mp3 --model large --language Korean
나는 잇섭님의 유튜브 영상으로 테스트 해 보았다.
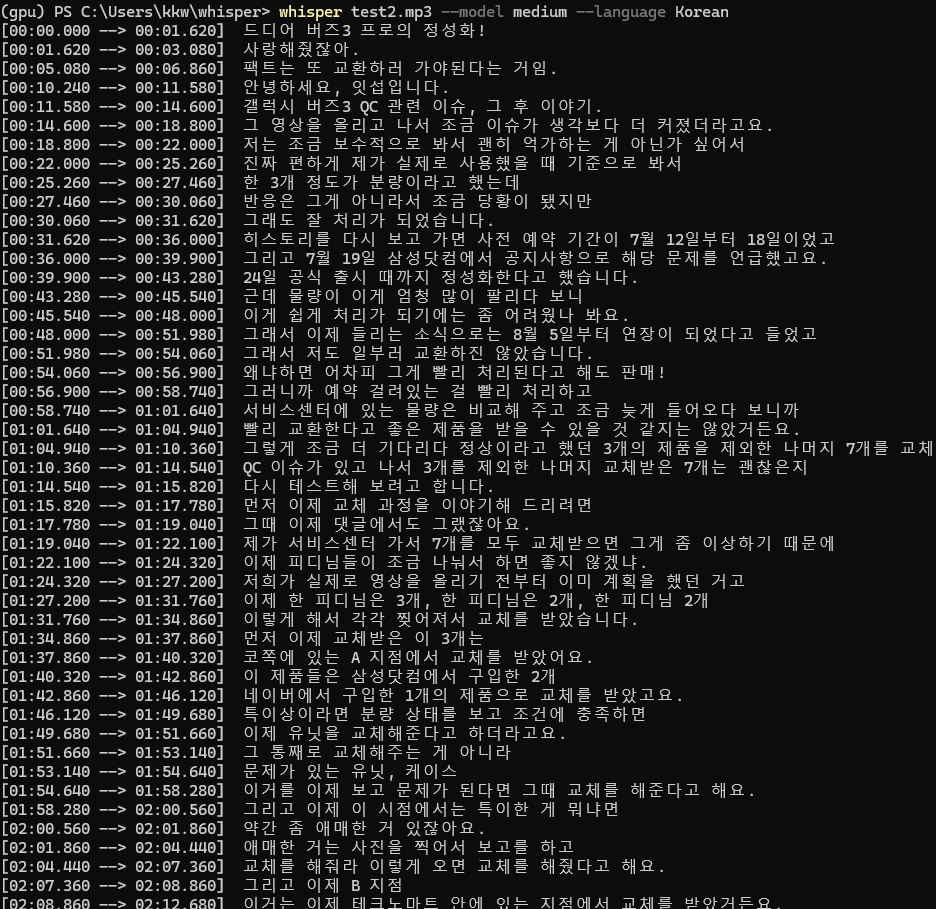
생각보다 잘 되는 것을 알 수 있다.
하지만 중간중간 어색한 단어들이 있어서 medium모델 말고 large모델을 써보려고한다.

필자의 GPU의 VRAM은 16GB이므로 large모델을 사용할 수 있다.
whisper test2.mp3 --model large --language Koreanlarge모델로 다시 돌려보자!
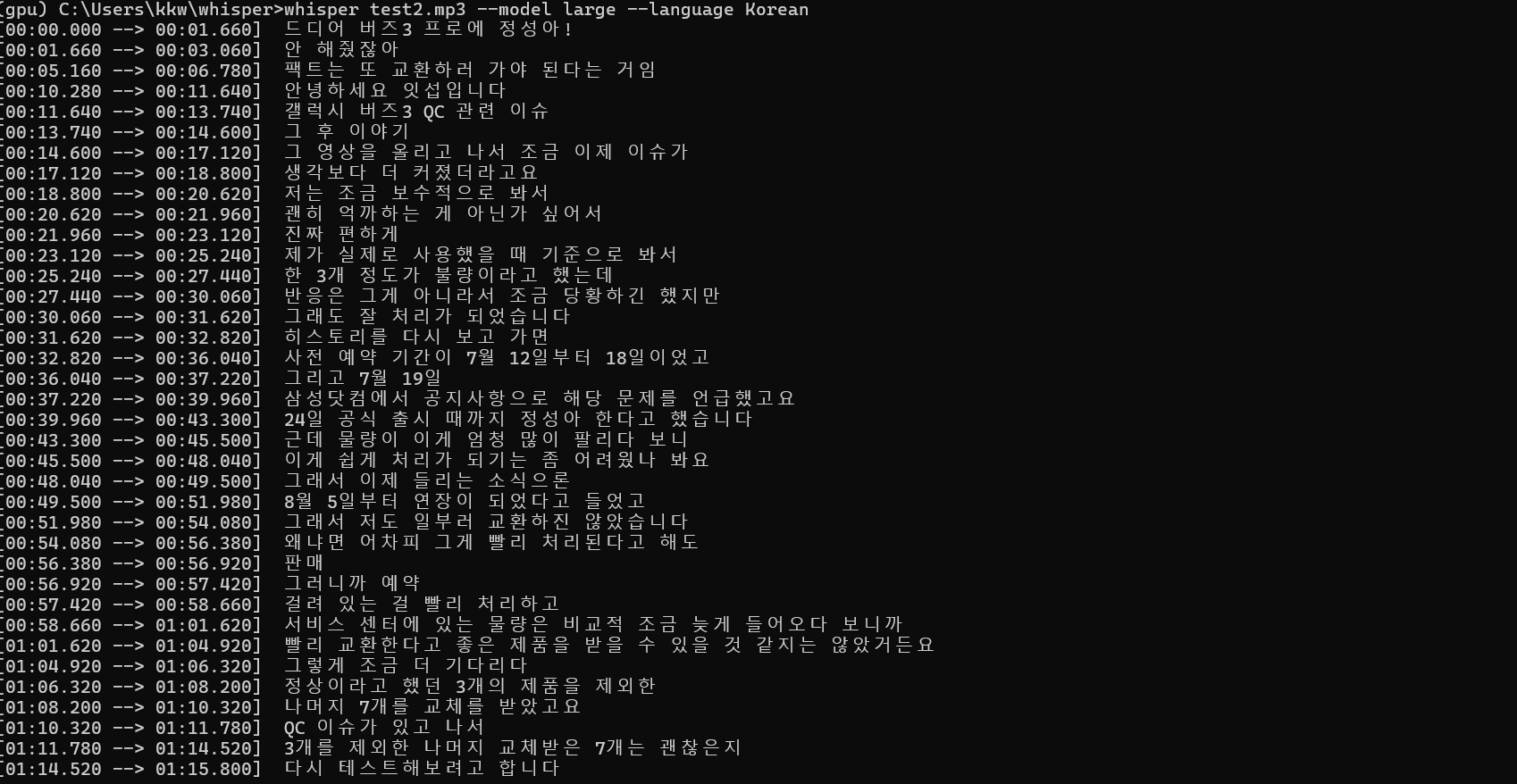
첫 문장은 조금 이상하지만 대부분의 문장들이 훨씬 정확하게 인식되었다.
지금은 간단한 테스트 수준으로 사용해 보았지만 파이썬으로 응용한다면 활용방법은 엄청 다양할 것 같다. 그리고 생각보다 속도가 무척 빨라서 놀라웠다.